
In my previous post, I explained how to regain access to a HyperFlex controller when ACI fails to update the IP to MAC mappings in the endpoint table by enabling the IP Aging option.
In this post I’ll show you how I reduced that failover time to about one minute.
To see if I could reduce the failover time, I turned to one of the best documents Cisco has ever produced for ACI – the ACI Fabric Endpoint Learning White Paper
And sure enough, I found that:
First-generation leaf switches cannot reflect IP address movement between two MAC addresses on the same interface with the same VLAN to the endpoint database. This sort of IP address movement may occur in a high-availability failover scenario in which GARP typically is used to update IP to MAC relation on upstream network devices. This behavior is resolved by enabling the GARP-based EP Move Detection option
And since my HyperFlex nodes are indeed connected to 1st generation ACI N9K-C9336PQ switches, this is exactly what I tried next:
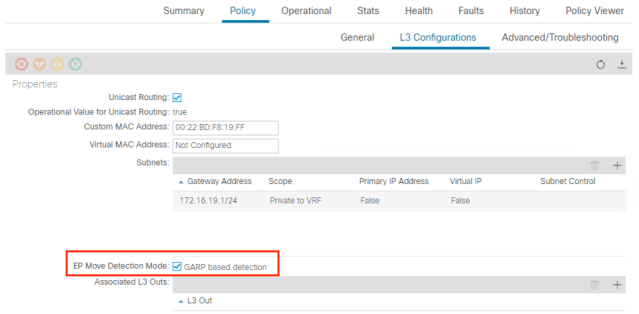
The curious thing about this option is that appears under the L3 Configurations tab but ONLY if ARP Flooding is enabled under the General tab.
Time to set up a test to see how much faster the failover is with the GARP Based Detection option enabled for the Bridge Domain
Test Plan
For the record, my test platform is running HyperFlex Data Platform v4.0(2d) (the current recommended latest version) and connected to ACI N9K-C9336PQ switches running v14.2(4i) . The APIC is running v4.2(5n).
Recall, my physical setup is like this:
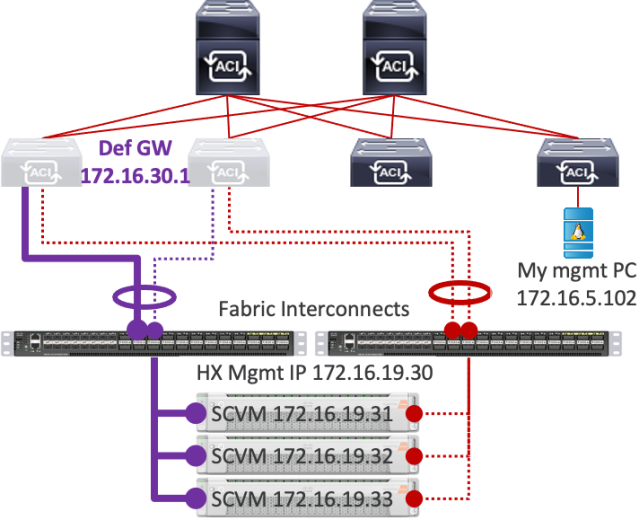
As I write this, the SCVM that has taken on the 172.16.19.30 management IP address is 172.16.19.31 with MAC address 00:0C:29:90:F4:70
apic1# show endpoints | grep "172\.16\.19\.3[0-3]" 00:0C:29:82:4F:B2 172.16.19.33 learned 101 eth1/32 vlan-119 not-applicable 00:0C:29:90:F4:70 172.16.19.31 learned 101 eth1/32 vlan-119 not-applicable 00:0C:29:90:F4:70 172.16.19.30 learned 101 eth1/32 vlan-119 not-applicable 00:0C:29:A9:B7:0D 172.16.19.32 learned 101 eth1/32 vlan-119 not-applicable
Armed with the information that the MAC address bound to the Mgmt IP address is shared 172.16.19.31 (the SCVM IP on ESXi host #1), my plan is to put ESXi host #1 into HX Maintenance Mode to force the election of another Mgmt SCVM and measure how long my Mgmt PC looses connectivity to the Mgmt IP address.
To do this I have set up:
- A continuous ping from my mgmt PC to 172.16.19.30 – I’m using PowerPing to do this so I get timestamps
- tcpdump sessions on the SCVMs capturing only ARP packets so I can see the Gratuitious ARP requests and replies.
- an endless loop issuing the command
vsh_lc -c "show system internal epmc endpoint ip 172.16.19.30"on the ACI APIC- The purpose of this command was to see when ACI’s COOP database was updated to show a different second IP address on the same host as 172.16.19.30
What I expected to happen is that once the two remaining SCVMs discover that 172.16.19.30 has failed, they will elect another SCVM to host the 172.16.19.30 address, and that VM will send gratuitous ARP requests to ensure ACI updates its endpoint table and my management IP will be able to gain access to the management IP again.
Test Results
Here’s the timeline of what happened. It wasn’t quite like I expected
| Time | Action |
| 14:18:40 | Initiate HyperFlex Maintenance Mode for ESXi Host#1 |
| 14:19:32 | SCVM#1 answers ARP request for 172.16.19.30 from 172.16.19.33 so is still online |
| 14:19:33 | SCVM#1 answers ARP request for 172.16.19.30 from 172.16.19.32 so is still online |
| 14:19:44 | Last ping reply recieved from 172.16.19.30 on the Mgmt station, indicating HX Mgmt IP is offline from this point |
| 14:19:56 | SCVM #3 starts sending contunuous ARPs for 172.16.19.30 to FF:FF:FF:FF:FF:FF |
| 14:20:17 | SCVM #2 also starts sending contunuous ARPs for 172.16.19.30 to FF:FF:FF:FF:FF:FF |
| 14:20:39 | SCVM #2 starts replying to ARPs for 172.16.19.30 , first to a specific MAC address, then… |
| 14:20:40 | SCVM #2 starts sending contunuous ARP replies for 172.16.19.30 to FF:FF:FF:FF:FF:FF |
| 14:20:40 | COOP database starts showing endpoint 172.16.19.30 is now shared with 172.16.19.32 indicating that the leaf switch has updated the COOP database on receipt of the ARP reply to FF:FF:FF:FF:FF:FF |
| 14:20:41 | Mgmt Station gets replies from 172.16.19.30 |
| 14:20:59 | SCVM #2 starts sending GARP requests to/from 172.16.19.30 to destination MAC FF:FF:FF:FF:FF:FF |
What I expected would have happened is that the GARP requests would have been sent at about 14:20:40 – rather than a string of ARP replies. However, it seems the ARP replies had the same effect.
Total failover time based on last ping reply received from SCVM#1 to first reply from SCVM#1: 14:20:41-14:19:44=00:57 – just inder one minute, which is far better than the 12 minutes I achieved last time.
Conclutions:
- ACI treats Gratuitous ARP replies just as you would expect GARP requests to be treated – in other words, ACI learns L2/L3 info from ARP replies sent to MAC FF:FF:FF:FF:FF:FF.
- In ACI, by enabling
- IP Aging in System Settings > Endpoint Controls, and…
- …in the the ACI BD where 1st generation switches are used
- ARP Broadcasting, and
- GARP based detection for EP Move Detection Mode
- HyperFlex management IP address failover when used in conjunction with ACI can be reduced to approximately one minute.
RedNectar
Postscript
While preparing to write this, I recorded my steps – it’s on YouTube but the transition to YouTube quality makes it almost impossible to see clearly. But if you have 7 mins to spare (Tip: play it back at double speed and on a 34″ monitor if you have one) the link is here: https://youtu.be/OxCEOAyKcSw
