Problem: You are designing a spreadsheet where IP addresses are to be entered. Probably with subnet masks as well. You want to ensure that the IP addresses and subnet masks entered are valid.
In this series I will explain how this is done, plus a few other IP address manipulating tricks in Excel.
TL;DR
Excel’s validation criteria formua must be less than 255 characters, so I had to find compromises. Here are 3 formulas you can use to validate that a legal IP address has been typed in cell C8 – but each one has a flaw;
Compromise#1: Doesn’t check for more than three dots
=AND(--LEFT(C8,FIND(".",C8)-1)<224,--LEFT(C8,FIND(".",C8)-1)>0,ISNUMBER(--SUBSTITUTE(C8,".","")),--MID(SUBSTITUTE(C8,"."," "),6,5)<256,--MID(SUBSTITUTE(C8,"."," "),15,7)<256,--MID(SUBSTITUTE(C8,"."," "),22,10)<256)
Compromise#2: Doesn’t check first octect for zero and allows negatives
=AND(LEN(C8)-LEN(SUBSTITUTE(C8,".",""))=3,--LEFT(C8,FIND(".",C8)-1)<224,ISNUMBER(--SUBSTITUTE(C8,".","")),--MID(SUBSTITUTE(C8,"."," "),6,5)<256,--MID(SUBSTITUTE(C8,"."," "),15,7)<256,--MID(SUBSTITUTE(C8,"."," "),22,10)<256)
Compromise#3: Doesn’t check for spaces or negative octets
=AND(LEN(C8)-LEN(SUBSTITUTE(C8,".",""))=3,--LEFT(C8,FIND(".",C8)-1)<224,--LEFT(C8,FIND(".",C8)-1)>0,--MID(SUBSTITUTE(C8,"."," "),6,5)<256,--MID(SUBSTITUTE(C8,"."," "),15,7)<256,--MID(SUBSTITUTE(C8,"."," "),22,10)<256)
Read on to see the foolproof formula and see how these work, Especially that double minus sign — notation!
Validating IP Address Entries in Excel
Firstly you need to understand that you can add validation to any Excel cell by selecting a cell then choosing Data > Validation, (in the Data Tools section of the ribbon). In this case, use a custom criteria based on a formula.
Now come the tricky bit. The formula has to be less than 255 characters long, and although there may be more elegant ways of expressing the formula below, I haven’t found one that uses fewer than 262 characters, so you have to choose a compromise. Even after compromising, the formula is only good for cells that have 2 to 4 characters in the cell reference. In other words, this formula won’t work in cell A1000, or AA100 or AAA10 because the cell reference is too large and makes the formula spill over 255 characters.
Formula for validating IP addresses
The formula below is for cell C8, and has been padded with line breaks and extra spaces for readability. This version is way past the 255 character limit, so check below for a compromise that suits you.
= AND(
LEN(C8)-LEN(SUBSTITUTE(C8,".","")) = 3,
--LEFT(C8,FIND(".",C8)-1) < 224,
--LEFT(C8,FIND(".",C8)-1) > 0,
--MID(SUBSTITUTE(C8,"."," "),6,5) < 256,
--MID(SUBSTITUTE(C8,"."," "),15,7) < 256,
--MID(SUBSTITUTE(C8,"."," "),22,10) < 256,
ISNUMBER(--SUBSTITUTE(C8,".",""))
)
And this is how it works:
The AND function is to ensure all the following conditions are met. The first condition checks to see if there are precisely three “dots” in the IP address by replacing the “.” characters with null strings i.e SUBSTITUTE(C8,”.”,””). If there are just three “.” characters then the resulting string will be three characters shorter than the whole string with the “dots” included:
LEN(C8)-LEN(SUBSTITUTE(C8,".","")) = 3,
The next condition is to check that the first octet is less than 224 (if you wished to allow multicast addresses, you would check that the first octet is less than 240). So simply extract the characters to the left of the first dot FIND(“.”,C8)-1 and check that the result is less than 224.
--LEFT(C8,FIND(".",C8)-1) < 224
But hold on – what are those two minus signs doing before the LEFT function?
Well, the problem is that the LEFT returns a string value, and if you compare a sting value with a numeric value like 224, the string value will always be larger, so in Excel, a test of:
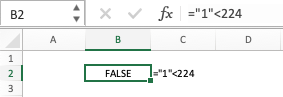
="1"<224
will always yield a result of FALSE
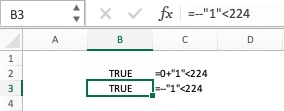
However, if you perform a numeric operation on the string, like adding zero, or finding the negative value of the string, Excel automagically transforms the string into a number. So, in the case above, the double negative is used to turn the string result into a numeric result so that the comparison works the way you expect. If the double negative worries you, add a 0 to the result instead. So instead of –LEFT(C8,FIND(“.”,C8)-1) < 224 use:
0 + LEFT(C8,FIND(".",C8)-1) < 224
and you will get the same result. And it uses the same number of characters.
The next comparison is exactly the same as the previous, except it is checking that the first octet of the IP address is larger than zero.
--LEFT(C8,FIND(".",C8)-1) > 0
So that takes care of the first octet, which we extracted by using the LEFT() function. But to extract the second and subsequent octets requires a but more lateral thinking.
You could try and extract the second octet by looking for the text between the first and second dots. Which is how we mentally do it. But in Excel this would be the mind-blowingly complicated:
=--LEFT(MID(C8,FIND(".",C8)+1,4),FIND(".",MID(C8,FIND(".",C8)+1,4))-1)
and which would chew up far too many of our precious 255 character limit.
But a far more elegant way (the basic idea for which I stole from one of the references below, many of them use a similar approach) is to expand the ip address into sections by replacing the dots with a number of spaces (four in this case), and then extracting that portion of the string where the second octect must reside.
The SUBSTITUTE(C8,”.”,” “) part takes care of replacing the dots with four spaces. So IP addresses of 1.2.3.4 and 123.145.167.189 get expanded to (using the ∙ character to represent spaces to make them easier to count):
1∙∙∙∙2∙∙∙∙3∙∙∙∙4 123∙∙∙∙145∙∙∙∙167∙∙∙∙189 123456789-123456789-12345
and if you now extract 5 digits from this string beginning with digit 6, MID(SUBSTITUTE(C8,”.”,” “),6,5) you will get either 2∙∙∙∙ or ∙∙145. Using the double-negative trick again turns either of these results into a number that can be checked to ensure it is less than 256, which is the condition that must be met for octets 2-4.
Moving onto the third octet, the logic is almost identical, except more spaces need to be inserted – six in fact. (The only reason 4 spaces were used for octet 2 was to save 2 characters out of our limited budget). And this time 7 digits are extracted starting with digit 15.
1∙∙∙∙∙∙2∙∙∙∙∙∙3∙∙∙∙∙∙4 123∙∙∙∙∙∙145∙∙∙∙∙∙167∙∙∙∙∙∙189 123456789-123456789-123456789-
And for the final octet, one more subtle change takes place. Some of the references I’ve read extract the next nine digits from the above to determine the last octet – but that fails if you enter 4 digits in the last octet, so to be sure to catch the condition where someone types 123.145.167.1891 the final check extracts 10 digits beginning with digit 22.
1∙∙∙∙∙∙2∙∙∙∙∙∙3∙∙∙∙∙∙4 123∙∙∙∙∙∙145∙∙∙∙∙∙167∙∙∙∙∙∙1891 123456789-123456789-123456789-1
The last condition is to check that no additional spaces or operators have been inserted ISNUMBER(–SUBSTITUTE(C8,”.”,””)). This helps ensures that no-one writes an IP address with negative numbers such as 1.2.3.-4. However it is not foolproof. An IP address of say 1.2.-1.2 will be converted to the string “12-12” which Excel with all its smarts sees a number. What number you say? Well, here’s a hint: 12-12 will be seen as 43811 in 2019, and as 44177 in 2020. Got it? 12-12 is seen as 12 December of the current year.
Choose your crutch – which condidtion do you want to remove?
Remember I mentioned that the solution is too long? Here it is again as a reminder, in a slightly different order:
= AND(
LEN(C8)-LEN(SUBSTITUTE(C8,".","")) = 3,
--LEFT(C8,FIND(".",C8)-1) > 0,
ISNUMBER(--SUBSTITUTE(C8,".","")),
--LEFT(C8,FIND(".",C8)-1) < 224,
--MID(SUBSTITUTE(C8,"."," "),6,5) < 256,
--MID(SUBSTITUTE(C8,"."," "),15,7) < 256,
--MID(SUBSTITUTE(C8,"."," "),22,10) < 256
)
To use the formula as a validation criteria, you have remove something to bring it below the 255 character limit.
Compromise#1: Ignore more than three dots
If you remove the first condition (LEN(C8)-LEN(SUBSTITUTE(C8,”.”,””)) = 3) then not only will you will be able to enter IP addresses that end in a training dot, you’ll be able to enter addresses like 1.2.3.4…5.6.7.8. As shown below though, you COULD catch this with conditional formatting, and do something about it, such as highlighting the cell in red.

Here’s a cut & pastable version of the testing validation criteria:
=AND(--LEFT(C8,FIND(".",C8)-1)<224,--LEFT(C8,FIND(".",C8)-1)>0,ISNUMBER(--SUBSTITUTE(C8,".","")),--MID(SUBSTITUTE(C8,"."," "),6,5)<256,--MID(SUBSTITUTE(C8,"."," "),15,7)<256,--MID(SUBSTITUTE(C8,"."," "),22,10)<256)
Compromise#2: Allow zeros and negatives
If you remove the second condition (–LEFT(C8,FIND(“.”,C8)-1) > 0) then not only will you allow IP addresses beginning with 0, but also negative addresses in the first octet. (The ISNUMBER(–SUBSTITUTE(C8,”.”,””)) condition attempts to take care of negatives in the other octets). Personally, I’d remove this condition before removing the check for 3 dots.

Here’s a cut & pastable version of the testing validation criteria without the test for the first octet being greater than 0.
=AND(LEN(C8)-LEN(SUBSTITUTE(C8,".",""))=3,--LEFT(C8,FIND(".",C8)-1)<224,ISNUMBER(--SUBSTITUTE(C8,".","")),--MID(SUBSTITUTE(C8,"."," "),6,5)<256,--MID(SUBSTITUTE(C8,"."," "),15,7)<256,--MID(SUBSTITUTE(C8,"."," "),22,10)<256)
Compromise#3: Allow spaces and negative octets
If you remove the condition (ISNUMBER(–SUBSTITUTE(C8,”.”,””))) then you can insert spaces into the IP address, which probably doesn’t matter much. It will also allow negative octets too, although even with the test some negatives get interpreted as dates anyway. I see this as the least useful test, and is my preferred test to omit.

And of course, in cut and pastable form:
=AND(LEN(C8)-LEN(SUBSTITUTE(C8,".",""))=3,--LEFT(C8,FIND(".",C8)-1)<224,--LEFT(C8,FIND(".",C8)-1)>0,--MID(SUBSTITUTE(C8,"."," "),6,5)<256,--MID(SUBSTITUTE(C8,"."," "),15,7)<256,--MID(SUBSTITUTE(C8,"."," "),22,10)<256)
So there you have it, data validation for IP addresses in a single cell. Next time I’ll show to validate subnet masks that can only contain the values 255,254,252,224,192,128 and 0 in any octet.
RedNectar
References:
https://www.excelforum.com/excel-formulas-and-functions/1100653-ip-address-conversion-formula.html
This is the one that got me started – Glenn Kennedy’s answer to an IP Address conversion formula
https://www.excelforum.com/excel-formulas-and-functions/1100653-ip-address-conversion-formula.html and https://www.pcreview.co.uk/threads/ip-address-validation.3651179/
Both these sites have Ron Rosenfield’s validation for cell I1 as
=AND(--LEFT(I1,FIND(".",I1)-1)<256,
--(MID(SUBSTITUTE(I1,".",REPT(" ",99)),99,99))<256,
--(MID(SUBSTITUTE(I1,".",REPT(" ",99)),198,99))<256,
--TRIM(RIGHT(SUBSTITUTE(I1,".",REPT(" ",99)),99))<256)
but this has too many false positives. For instance, it would allow an IP address of 244.244.244.244 which is invalid.
https://www.excelforum.com/excel-formulas-and-functions/1253877-subnetting-validation.html
Apart from the fact that it didn’t test the last octet for values greater than 255, XOR LX‘s suggestion of:
=SUMPRODUCT(N(LOG(1+MID(SUBSTITUTE(B1,".",REPT(" ",10)),{1,11,21,31},10),2)<=8))
was interesting, but a) you can’t use SUMPRODUCT in cell Validation criteria, b) when expanded to make it work takes more characters than the solution I’ve used and c) was missing the compaison criteria. It should have been:
=SUMPRODUCT(N(LOG(1+MID(SUBSTITUTE(B1,".",REPT(" ",10)),{1,11,21,31},10),2)<=8))=4
It was interesting because it made use of the fact that the log base 2 of 256 is 8, and less than 8 for any number less than 256. The SUMPROUCT counts the number of octets that have a log base 2 equal to or less than 8, which of course should be 4.

Pingback: Newsletter: August 3, 2019 – Notes from MWhite